Cómo un API server debe responder a queries muy largas: the RESTful way
Hoy voy a tratar de responder una pregunta que nos ha perseguido desde el principio de los tiempos: ¿cómo lidiar correctamente con HTTP GET queries que son demasiadas largas para ser procesadas por el backend?. Y no, hacer un POST y obtener el resultado es incorrecto. Bueno... si, pero no... Seguí leyendo y te explico bien.

El origen del problema.
Escenario: estamos a cargo de un REST API backend que tiene que buscar datos de poblaciones por nombre de ciudad. Para eso exponemos http://example.com/api/censo?q= y pasamos los nombres de las ciudades que queremos. por ejemplo
http://example.com/api/censo?q=santiago,brasilia,buenos%20aires,tijuana,barcelona
Entonces nosotros buscaríamos en la base de datos la información para las ciudades de Santiago, Brasilia, Buenos Aires, Tijuana, Barcelona y se devolvería en la respuesta. Hasta ahí todo bien y normal. Una llamada, una colección de datos de respuesta y el frontend felíz. Con una función map() podría dar formato y mostrar al usuario el resultado en pantalla. El problema que se puede presentar es que un user perfectamente podría buscar 100, 200 o 1000 ciudades al mismo tiempo...
En teoría, no hay problema. El RFC 2616 especifica que las URLs no tienen límite de caracteres. Uno podría hacer una query con el texto completo del Quijote de la Mancha y el servidor debería procesarlo.
The HTTP protocol does not place any a priori limit on the length of a URI. Servers MUST be able to handle the URI of any resource they serve, and SHOULD be able to handle URIs of unbounded length if they provide GET-based forms that could generate such URIs.
Pero la realidad es tirana y termina imponiendo sus limites. En una infraestructura moderna seguro hay uno o varios gateways, proxys, etc que limitan la cantidad de caracteres que puede puede procesar el sistema...
Límite de caracteres de una URL.
Navegadores:
- Microsoft Internet Explorer: 2.083 caracteres
- Microsoft Edge: 2.083 caracteres
- Google Chrome: 32.779 caracteres
- Mozilla Firefox: more than 64.000 caracteres
- Apple Safari: more than 64.000 caracteres
- Google Android: 8.192 caracteres
Servidores web / CDNs
- Apache: 8.177 caracteres
- NGINX: 4.096 caracteres
- Microsoft IIS: 16.384 caracteres
- Fastly (CDN): 8.192 caracteres
- Amazon Cloudfront (CDN): 8.192 caracteres
- Cloudflare (CDN): 32.768 caracteres
Fuente: SISTRIX
Soluciones: el bueno, el malo y el feo.
Tenemos varios caminos para sortear estas limitaciones
El bueno.
Lo primero que se nos puede venir a la mente es desde el frontend detectar el tamaño de la query antes de mandarla. Si la longitud total de la URL generada es superior a 2000 caracteres, entonces podríamos pedir la query en varios requests al servidor. Volviendo a nuestro ejemplo, si el limite de la URL fuera de 50 chars entonces se podría quedar solucionar así:
http://example.com/api/censo?q=santiago,brasilia
http://example.com/api/censo?q=buenos%20aires
http://example.com/api/censo?q=tijuana,barcelona
Cómo pro, no necesitariamos modificar el backend, todo se mantiene RESTful cómo fue diseñado en un principio. La contra es que el front ahora tiene más trabajo: implementar funciones para partir las cadenas, enviar múltiples requests al server, juntar todas las respuestas y componer un objecto para ser procesado. También hay que prever que hacer en el evento que uno de los requests falle.
El malo.
Nuestro server devuelve un hermoso status 414 y que dios se apiade del alma del cliente. El frontend implementa un alert()/notificación/snack informando que la query falló por elegir muchas ciudades. Que elija menos ciudades y fin del asunto.
NOTA: esto podría ser un chiste, pero lo he visto en producción demasiadas veces cómo para saber que no son casos aislados.
El feo.
Si no puedo usar GET entonces F**k It 🤬. Creamos un endpoint POST en el backend con el mismo servicio/lógica que http://example.com/api/censo y la query q=santiago,brasilia,buenos%20aires,tijuana,barcelona ahora se convierte en el JSON
{
"q": "santiago,brasilia,buenos%20aires,tijuana,barcelona"
}
El resultado vuelve en el body y todos felices. Hasta que te das cuenta que rompiste cualquier dejo de RESTful del sistema. Se perdió el cache (sin tener que hacer otra cochinada para soportar cache en POST) así que cada request se va tener que volver a procesar. Existe un claro peligro de abuso de los desarrolladores: si con POST no tengo limite ¿por qué no simplemente pedimos todas las queries, largas o cortas, vía POST? Finalmente y para los puristas: una operación que por diseño no es idempotente ahora se convirtió en idempotente, adiós estandar HTTP, te vamos a extrañar.
Esta seguramente es la reacción de Sir Tim Berners Lee al verte hacer eso
The best RESTful way (en mi humilde opinión).
Existe otra salida que considero elegante sin romper los protocolos de HTTP y balanceando bastante bien la experiencia del consumidor de la API. Para esto hice una prueba de concepto con un servidor web en NodeJS con el framework Express. Pueden encontrar el repositorio en GitHub.
Dejo atrás el ejemplo de ciudades; el servidor es un buscador de libros que usa el índice del proyecto Gutenberg (https://gutendex.com) y que se ejecuta en localhost:3001. Cuenta con 2 endpoints
/api/books(GET,POST)/api/books/query(GET)
/api/books?q=charles devuelve todos los libros donde aparezca la palabra "charles" en los metadatos. Si todo funcionó correctamente el servidor devuelve
< HTTP/1.1 200 OK
< x-powered-by: Express
< access-control-allow-methods: GET, OPTIONS
< content-type: application/json; charset=utf-8
< Date: Sat, 24 Dec 2022 12:50:08 GMT
< Connection: keep-alive
< Keep-Alive: timeout=5
< Transfer-Encoding: chunked
Aquí un punto importante, el header access-control-allow-methods ya nos está indicando que metodos soporta el endpoint. Una persona que no sabe absolutamente nada del servicio puede tener una información básica de que puede o no puede hacer. Arbitrariamente puse un límite de 10 caracteres a la query para simular un límite. En un proyecto real uno podría poner 2.000, por ejemplo.
Volviendo, la llamada anterior devuelve un resultado normal y feliz de la operación. Pero ¿qué pasa si quiero buscar por arriba del límite de la URL? Por ejemplo http://localhost:3001/api/books?q=charles%20dickens. Acá se pone la cosa interesante, veamos el gráfico
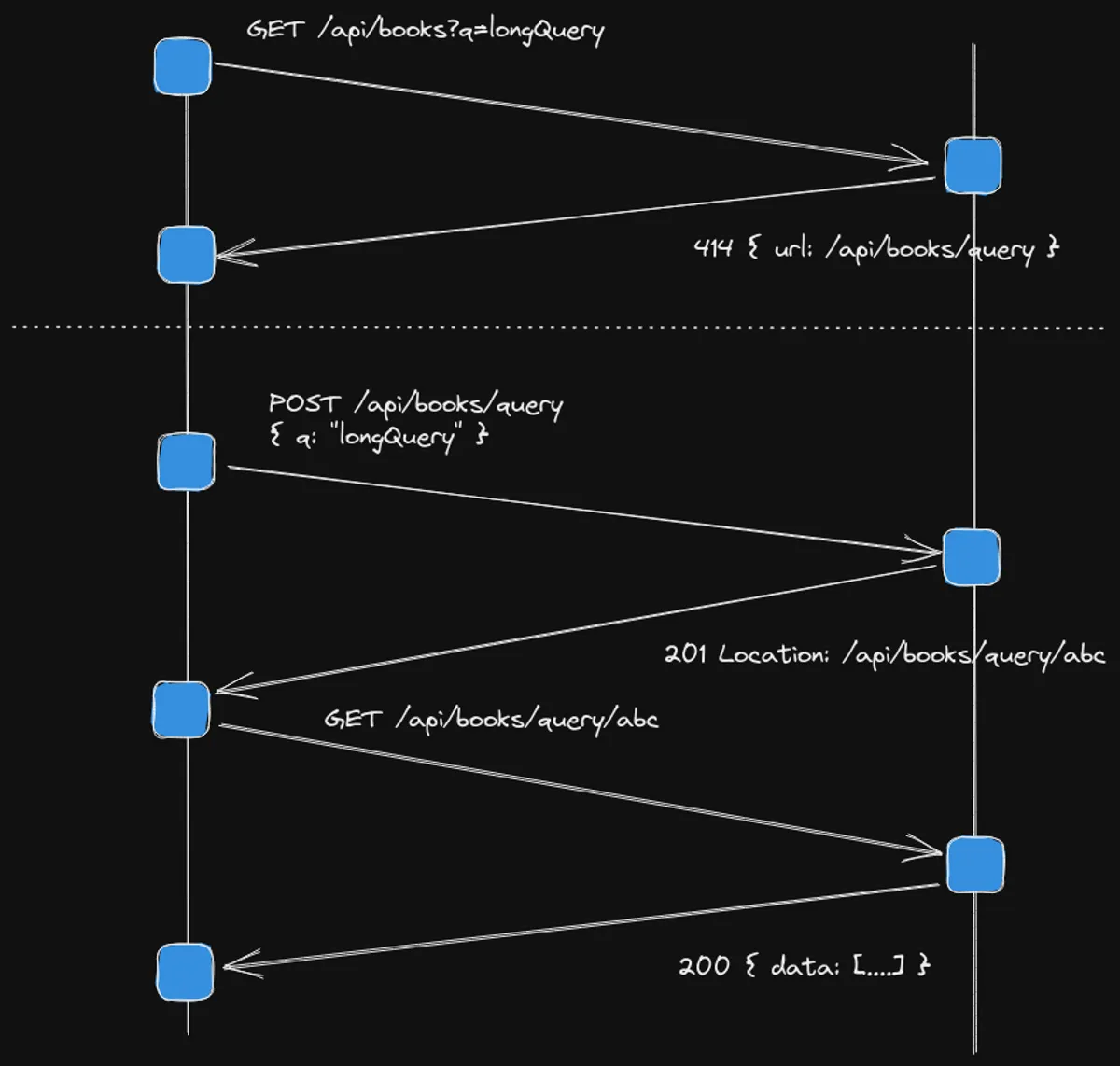
Si el cliente hace una petición larga, entre el límite que pusimos y el que soportan los servidores intermedios, nuestro backend responderá con
< HTTP/1.1 414 URI Too Long
< x-powered-by: Express
< access-control-allow-methods: POST, GET, OPTIONS
< content-type: application/json; charset=utf-8
< Date: Sat, 24 Dec 2022 12:48:34 GMT
< Connection: keep-alive
< Keep-Alive: timeout=5
< Transfer-Encoding: chunked
Y en el body
{
"message": "Query is too long. Use query on POST method",
"url": "http://localhost:3001/api/books/query"
}
Estamos indicando claramente que hay un problema y cómo solucionarlo. Para un developer eso es el cielo. Ahora sabiendo eso, se tiene que modificar el frontend para detectar cuando la URL es muy larga, optimizando de esta manera el primer fallo: si la URL es mayor a 10 caracteres entonces sabemos que va a fallar siempre.
Para solucionarlo, simplemente tenemos que hacer un request POST a /api/books/query con la query en el body
{
"q": "charles dickens"
}
De no haber problemas el server nos responde con el status 201 created y el Location de la query. Para evitar inconsistencias también devuelvo la URL del location en el body de la respuesta.
< HTTP/1.1 201 Created
< X-Powered-By: Express
< Access-Control-Allow-Methods: POST, GET, OPTIONS
< Location: http://localhost:3001/api/books/query/ef42f12a2e9927ce56b952607ee13de5101df39ee12db74e8bef2eef8c100844
< Content-Type: application/json; charset=utf-8
< Content-Length: 112
< ETag: W/"70-5tuhk+QlS7v0H3XW4vx2qZpjSzg"
< Date: Sat, 24 Dec 2022 16:48:18 GMT
< Connection: keep-alive
< Keep-Alive: timeout=5
{
"url": "http://localhost:3001/api/books/query/ef42f12a2e9927ce56b952607ee13de5101df39ee12db74e8bef2eef8c100844"
}
En el caso de que se vuelva a mandar la misma query por POST devuelvo el status 200 y el resto todo igual. Ahora simplemente tomamos la URL y hacemos el request a http://localhost:3001/api/books/query/ef42f12a2e9927ce56b952607ee13de5101df39ee12db74e8bef2eef8c100844... La primer llamada va a tardar pero si refrescamos varias veces el cache va responder inmediatamente. Lo que noté es que el middleware que usé en el ejemplo express-api-cache no responde con 304 que sería lo correcto. Pero si usas Nginx u otro reverse proxy debería comportarse correctamante.
Cómo funciona internamente.
Show me the code
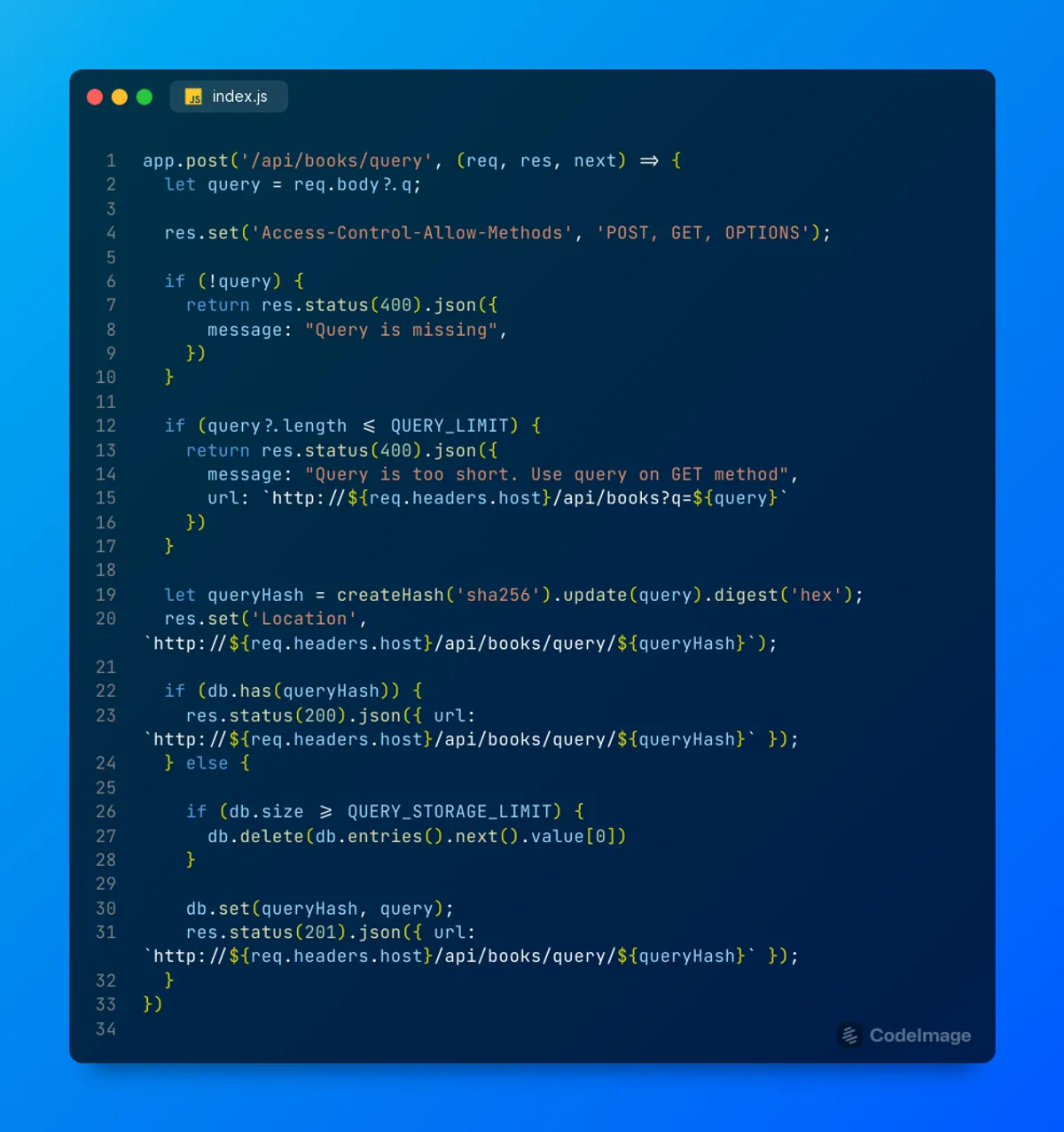
La lógica es bastante simple. Cuando un user realiza el POST se genera un hash sha-256y se almacena en un hashmap siendo la query original el valor y el hash la key. Idealmente debería almacenarse en Redis u otra base de datos para que el servicio se mantenga stateless. Es importante destacar dos carácteristicas importantes
- Evitar el abuso de la API. Si la query es menor que la cantidad máxima que soporta la API
GET/api/books, entonces retorna un status400e indica el correcto endpoint a utilizar. - Los registros de hash son finitos. Para evitar problemas de performance y sabiendo que las queries largas deberian ser la excepción y no la regla, el hashmap implementa la rotación de registro. Cuando se pasa el
QUERY_STORAGE_LIMIT, se elimina el primer elemento delMap()para luego agregar el nuevo. En Redis se puede hacer lo mismo utilizandoEXPIRE
Para ir cerrando
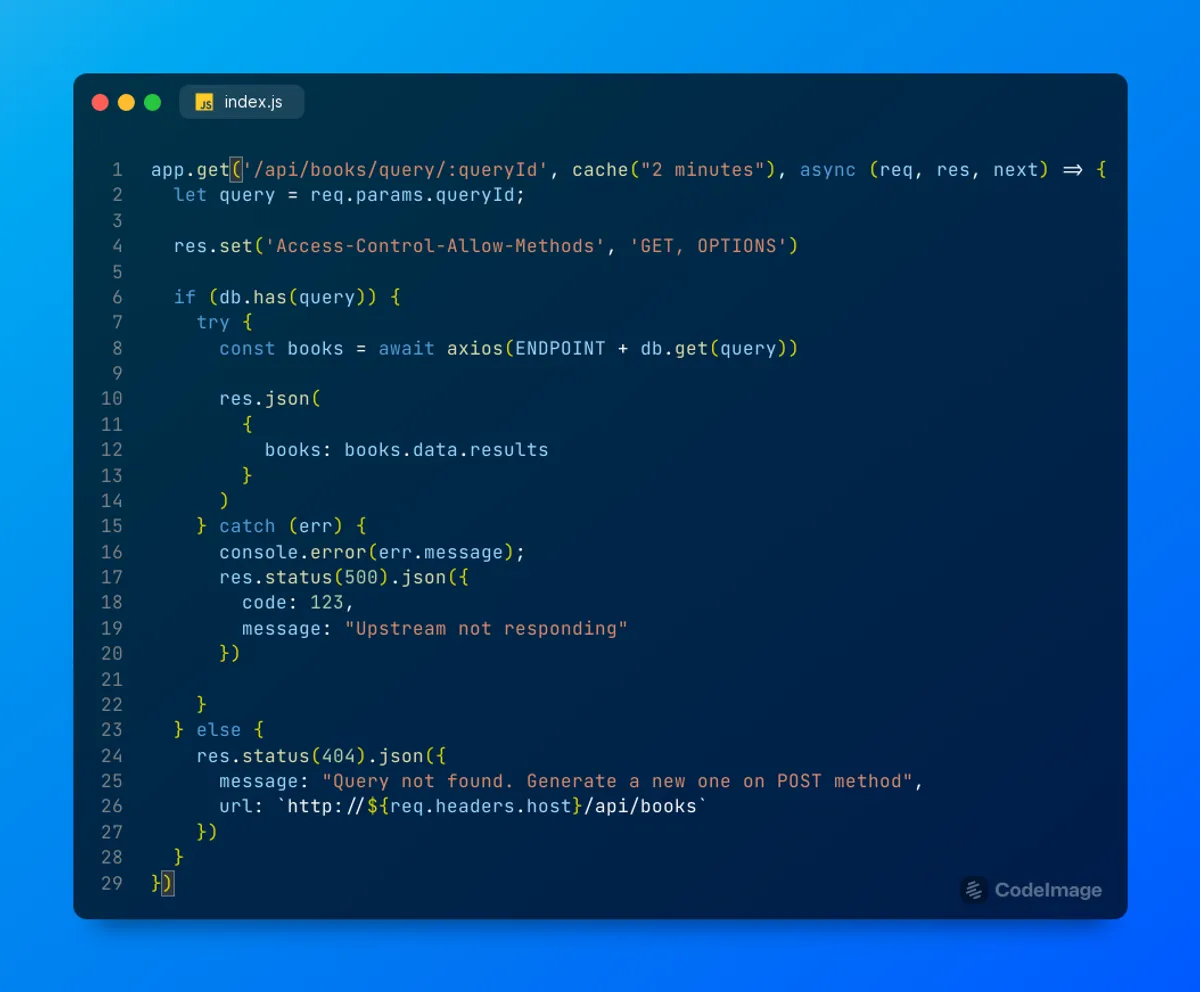
Si el hash se encuentra en el storage, entonces se pasaría el valor al servicio correspondiente. En el ejemplo el valor es la query para buscar libros en la API de Gutemberg. En caso de que el hash no se encuentre, entonces muy amablemente se responde con un status 404 y los pasos a seguir para generar una nueva query larga. ¿Qué más se puede pedir?
{
"message": "Query not found. Generate a new one on POST method",
"url": "http://localhost:3001/api/books/query"
}
Foto de Minator Yang en Unsplash